







I. Motivation▲
û quoi peut-on rûˋsumer le Web traditionnel que l'on connaûÛt actuellementô ? Trû´s simplement, c'est la somme d'Internet, de documents et de liens. La situation est rûˋsumûˋe dans la premiû´re figureô : elle servira de base d'exemple pour expliquer ce que ce Web actuel peut avoir comme problû´mes.
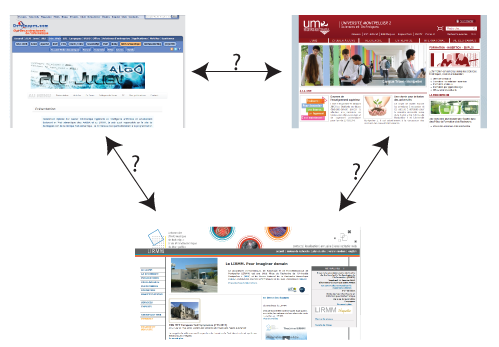
Quel est le lien entre les pages d'accueil de ces trois sites Webô ? Quelqu'un qui me connaûÛt personnellement peut le savoir, mais une machine ou une personne ne me connaissant pas ne peut pas le savoir. Ce sont les pages d'accueil de mon site personnel, de l'universitûˋ oû¿ j'ai poursuivi mes ûˋtudes supûˋrieures et de mon laboratoire actuel qui est rattachûˋ û cette mûˆme universitûˋ.
Ce bref petit exemple montre bien un des problû´mes du Web actuelô : les donnûˋes qui y sont contenues sont trû´s mal structurûˋes. Malgrûˋ tout, un humain, aprû´s une lecture de ces pages, peut faire le lien entre ces trois pages, alors qu'une machine, en est incapable. L'un des buts d'avoir une meilleure structuration est de rendre la machine capable de comprendre ceci toute seule.
Un autre problû´me est la trû´s grosse difficultûˋ (voire l'impossibilitûˋ) de crûˋer des applications ô¨ô intelligentesô ô£, û cause du manque de donnûˋes libres, et surtout structurûˋes, disponibles sur le Web .
Mais actuellement, il y a plein d'applications qui existent et qui utilisent de multiples sources de donnûˋes, mûˆme si elles ne sont pas structurûˋes via des API Web. Oui, mais il existe quelques problû´mes avec ces applicationsô :
- la majoritûˋ des API Web sont propriûˋtairesô ;
- les applications sont basûˋes sur un ensemble de sources de donnûˋes fixesô ;
- il est impossible de faire des liens entre ces sources de donnûˋes, ou entre les donnûˋes contenues dans ces diffûˋrentes sources.
Les donnûˋes structurûˋes rûˋsolvent ce problû´me. Leur nom est dû£ aux liens entre ces donnûˋes structurûˋes
II. Fondations techniques▲
Les donnûˋes liûˋes sont basûˋes sur un mûˋlange de technologies du Web sûˋmantique et du Web actuel qui sontô :
- RDF, qui sera bientûÇt dûˋtaillûˋô ;
- HTTP pour accûˋder aux donnûˋes via le Webô ;
-
URIô :
- des identifiants uniques pour les entitûˋs sur le Web,
- des pointeurs sur les donnûˋesô ;
- les hyperliens.
Je ne dûˋtaillerai pas ici ce que sont HTTP et les hyperliens.
II-A. RDF en gûˋnûˋral▲
RDF (Resource Description Framework), est un standard dûˋcrivantô :
- des ressources, une ressource pouvant ûˆtre n'importe quoi (personnes, lieux, animaux, documents, concepts, etc.)ô ;
- la description de ces ressources par des attributs et des relationsô ;
- le framework contenant un modû´le de donnûˋes, des langages et des syntaxes.
Il est vrai que RDF est principalement un modû´le de donnûˋes, puisque les donnûˋes sont structurûˋes par des triplets (sujet, prûˋdicat, objet)ô :
- sujetô : une ressourceô ;
- prûˋdicatô : une propriûˋtûˋô ;
- objetô : un littûˋral ou bien une ressource.
Par exempleô :
- (Tour Eiffel, est crûˋûˋe, 1887)ô ;
- (Tour Eiffel, est situûˋe, Paris).
Avec ceci, on peut facilement en dûˋduire que la structure crûˋûˋe par ce modû´le est un graphe orientûˋ, dont les sujets et les objets sont les néuds et dont les prûˋdicats sont les arûˆtes orientûˋes. Voici un petit exemple dûˋcrivant les deux triplets ci-dessusô :
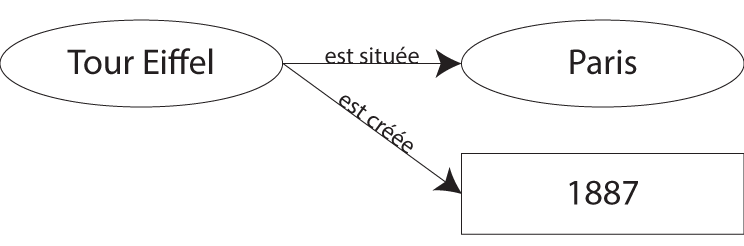
Les formes ovales reprûˋsentent des ressources et la forme rectangulaire reprûˋsente un littûˋral.
II-B. URI (Uniform Resource Identifier)▲
Une URI ûˋtend le principe d'URL, puisqu'il est de coutume d'utiliser une URL pour identifier de faûÏon unique un document Web. C'est d'ailleurs la principale diffûˋrence entre les deuxô : une URI reprûˋsente un objet unique (une personne, un lieu, un livre, etc.) et une URL un document Web. Comme exemple, on peut citer les trois faûÏons de reprûˋsenter une personne sur le Webô :
- la personne elle-mûˆmeô : http://jplu.developpez.com/julien#JPô ;
- le document RDF de cette personneô : http://jplu.developpez.com/julienô ;
- le document HTML de cette personneô : http://jplu.developpez.com/julien.html.
Seule la derniû´re adresse est une URL, puisqu'elle reprûˋsente un document Web. Ce qu'il faut aussi savoir, c'est que les sujets sont des URI, les propriûˋtûˋs sont des URI et les objets peuvent ûˆtre des URI. Pour expliquer ceci, reprenons l'exemple de la Tour Eiffel. Pour reprûˋsenter correctement ces triplets, il aurait fallu l'ûˋcrire de cette maniû´reô :
- (http://dbpedia.org/resource/Eiffel_Tower, http://dbpedia.org/ontology/location, http://dbpedia.org/resource/Paris)ô ;
- (http://dbpedia.org/resource/Eiffel_Tower, http://dbpedia.org/property/startDate, 1887).
DBPedia est la version donnûˋes liûˋes de Wikipûˋdia. Ce qui donne le graphe suivantô :
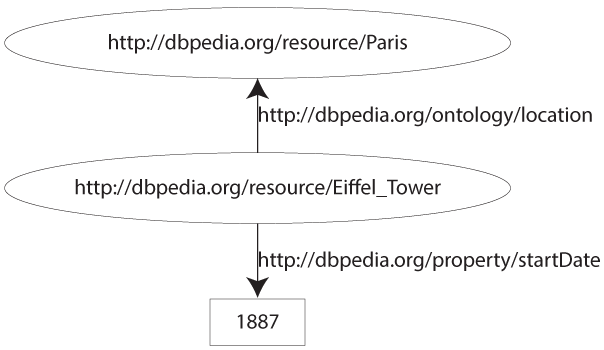
Maintenant que nous avons un beau graphe RDF, il reste encore une petite possibilitûˋ d'amûˋlioration ou, plutûÇt, un raccourci permettant d'amûˋliorer la lecture du graphe. Il consiste û raccourcir les URI des propriûˋtûˋsô : on appelle cela des CURIE, pour Compact URI. C'est un principe extrûˆmement simple qui consiste û attribuer un prûˋfixe aux URI des propriûˋtûˋs. Ici nous avons deux URI qui sontô :
- http://dbpedia.org/ontology/ô ;
- http://dbpedia.org/property/.
Ces deux URI sont appelûˋes des ô¨ô espaces de nomsô ô£. Nous allons donc attribuer un prûˋfixe û ces deux URI qui sont ô¨ô dbpedia-owlô ô£ et ô¨ô dbppropô ô£. Ainsi nous pouvons ûˋcrire les propriûˋtûˋs de maniû´re beaucoup plus courte comme ô¨ô dbpedia-owl:locationô ô£ et ô¨ô dbpprop:startDateô ô£. Chose moins commune, il est aussi possible d'attribuer une CURIE aux ressources de la mûˆme maniû´re en attribuant un prûˋfixe, ce qui permet de remplacer l'espace de noms ô¨ô http://dbpedia.org/resource/ô ô£ par ô¨ô dbpediaô ô£. Ce qui donnera maintenant pour les triplets et le grapheô :
- (dbpedia:Eiffel_Tower, dbpedia-owl:location, dbpedia:Paris)ô ;
- (dbpedia:Eiffel_Tower, dbpprop:startDate, 1887).
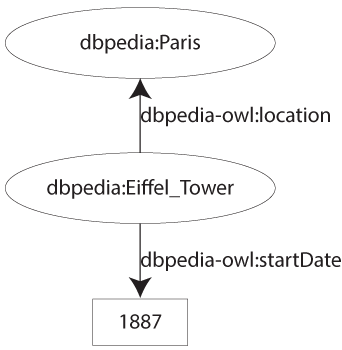
II-C. Littûˋral▲
Les littûˋraux occupent toujours la place d'objet dans un triplet et sont reprûˋsentûˋs par une chaûÛne de caractû´res. Ces chaûÛnes de caractû´res correspondent û ce que l'on appelle des ô¨ô types de donnûˋesô ô£ô : en gûˋnûˋral, ces types de donnûˋes sont les types de donnûˋes XSD de XML Schema (xsd:date, xsd:anyURI, xsd:integer, etc.). Si aucun type de donnûˋes n'est prûˋcisûˋ, alors, par dûˋfaut, on considû´re que la donnûˋe est du type ô¨ô xsd:stringô ô£. L'autre petite chose avec les donnûˋes non typûˋes est qu'on peut leur attribuer une langue (@fr, @en, etc.). Voyons tout ceci avec un petit schûˋmaô :
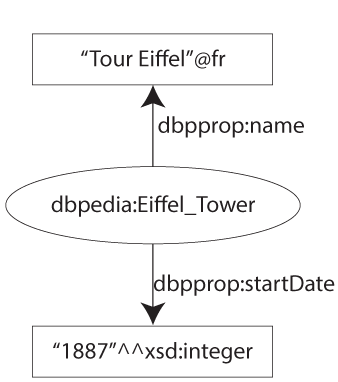
II-D. Turtle▲
Turtle est une syntaxe RDF parfaitement lisible par un humain. Son ûˋcriture est trû´s simple, puisque la principale rû´gle û retenir est que chaque triplet est sûˋparûˋ par ô¨ô .ô ô£. Il supporte bien entendu les CURIE via le terme ô¨ô @prefixô ô£ qui associe un espace de noms û un prûˋfixe. Voici un petit exemple de Turtleô :
@prefix dbpedia-owl: <http://dbpedia.org/ontology/> .
@prefix dbpprop: <http://dbpedia.org/property/> .
@prefix dbpedia: <http://dbpedia.org/resource/> .
@prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
dbpedia:Eiffel_Tower dbpedia-owl:location dbpedia:Paris
dbpedia:Eiffel_Tower dbpprop:startDate "1887"^^xsd:integer
dbpedia:Eiffel_Tower dbpprop:name "Tour Eiffel"@fr
dbpedia:Eiffel_Tower dbpprop:name "Eiffel Tower"@enPour davantage amûˋliorer la lecture, on peut utiliser deux autres petits raccourcisô :
@prefix dbpedia-owl: <http://dbpedia.org/ontology/> .
@prefix dbpprop: <http://dbpedia.org/property/> .
@prefix dbpedia: <http://dbpedia.org/resource/> .
@prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
dbpedia:Eiffel_Tower dbpedia-owl:location dbpedia:Paris ;
dbpprop:startDate "1887"^^xsd:integer ;
dbpprop:name "Tour Eiffel"@fr, "Eiffel Tower"@en .Si une ressource est dûˋcrite par plusieurs propriûˋtûˋs, il est possible de ne pas rûˋpûˋter û chaque fois cette ressource en dûˋbut de chaque ligne, tout simplement en mettant un ô¨;ô ô£ û la place du ô¨ô .ô ô£. Le second raccourci consiste û sûˋparer les objets correspondant û une mûˆme propriûˋtûˋ par une simple ô¨ô ,ô ô£.
Il existe d'autres syntaxes comme RDF/XML, N-Triples, N-Quads, et bien d'autres, mais je ne vous montrerai que du Turtle dans ce tutoriel pour la simple et bonne raison que c'est le format le plus simple û utiliser et surtout û lire.
II-E. Néuds anonymes▲
Un néud anonyme reprûˋsente, dans un graphe RDF, une ressource anonyme ou, plus simplement, une URI qui n'existe pas ou qui n'a pas d'identification. En Turtle, on note un néud anonyme en le prûˋfixant de ô¨ô _:ô ô£ suivi d'un nom quelconque. Dans un graphe, un néud anonyme est reprûˋsentûˋ par une forme ovale vide. Voici un petit exemple en Turtle et avec un grapheô :
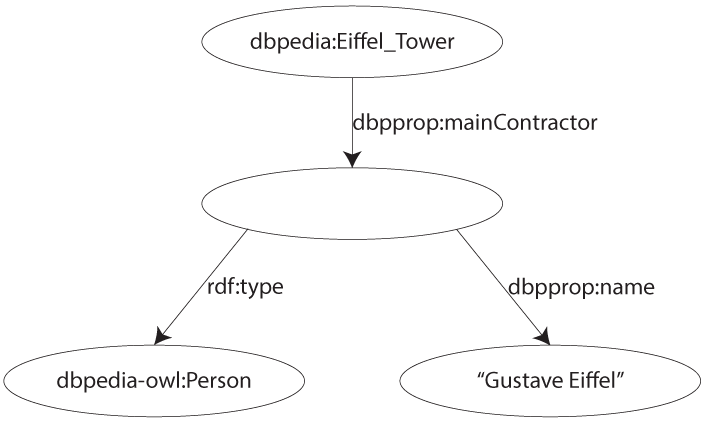
@prefix dbpprop: <http://dbpedia.org/property/> .
@prefix dbpedia: <http://dbpedia.org/resource/> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>.
dbpedia:Eiffel_Tower dbpprop:mainContractor _:GustaveEiffel .
_:GustaveEiffel rdf:type dbpedia-owl:Person ;
dbpprop:name "Gustave Eiffel" .Petite nouveautûˋ ici, la propriûˋtûˋ ô¨ô rdf:typeô ô£. Elle sert û dûˋcrire le type de la ressource associûˋe. Ici, on dûˋcrit un néud anonyme qui correspond û une personne. D'ailleurs, il est possible, en Turtle, de se passer d'ûˋcrire cette propriûˋtûˋ avec un autre petit raccourci en la remplaûÏant par ô¨ô aô ô£. Ce qui donne ceciô :
@prefix dbpprop: <http://dbpedia.org/property/> .
@prefix dbpedia: <http://dbpedia.org/resource/> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>.
dbpedia:Eiffel_Tower dbpprop:mainContractor _:GustaveEiffel .
_:GustaveEiffel a dbpedia-owl:Person ;
dbpprop:name "Gustave Eiffel" .III. RDFS et OWL▲
RDFS (Resources Description Framework Schema) et OWL (Web Ontology Language) sont deux standards du W3C pour la description respective des vocabulaires et des ontologies. û ce niveau, il n'est pas nûˋcessaire de comprendre ces deux standards, vous devez juste savoir trouver de quels vocabulaires ou de quelles ontologies vous avez besoin pour bien dûˋcrire vos donnûˋes, ainsi que de savoir lire leur documentation afin de bien utiliser les propriûˋtûˋs et les types de donnûˋes qui peuvent vous intûˋresser. Un article sera spûˋcialement dûˋdiûˋ û cette activitûˋ.
IV. Conclusion▲
Vous savez maintenant comment modûˋliser vos donnûˋes si vous voulez les publier sur le Web de donnûˋes. N'oubliez pas que ce tutoriel est une brû´ve introduction, il y manque beaucoup de choses. Il prûˋsente le minimum requis pour comprendre la faûÏon d'organiser les donnûˋes sur le Web de donnûˋes. Si j'ai ûˋveillûˋ votre curiositûˋ, vous trouverez deux autres tutoriels plus prûˋcis, un allant plus loin dans la dûˋfinition du RDF couplûˋe û un apprentissage de Jena et l'autre sur la crûˋation d'un fichier FOAF vous servant d'exemple pour commencer û ûˋcrire du RDF.
V. Remerciements▲
Merci û dourouc05metafire18, pour leurs propositions d'amûˋliorations ainsi qu'û ced et Claude Leloup pour leur relecture orthographique.