







I. Introduction▲
Dans mon article prûˋcûˋdent, que vous pouvez voir ici, j'avais trû´s vite introduit la notion d'ontologie, mais pas assez pour savoir rûˋellement ce que cela peut ûˆtre. Nous allons donc ici voir beaucoup plus en dûˋtail ce que peut ûˆtre une ontologie avec un domaine que l'on nomme la reprûˋsentation des connaissances. Je vous conseille donc avant de lire cet article de lire le prûˋcûˋdent.
La reprûˋsentation des connaissances est un systû´me dûˋfinissant une sûˋrie de classes et une sûˋrie de propriûˋtûˋs qui relient les classes. On peut aussi voir ûÏa comme une algû´breô : on a des ûˋlûˋments entre lesquels on dûˋfinit des opûˋrations. Petit rappel supplûˋmentaire dans le domaine du Web sûˋmantique, un concept correspond û une classe et une relation correspond û une propriûˋtûˋ.
II. Classes et propriûˋtûˋs▲
Dans mon article prûˋcûˋdent, je m'ûˋtais arrûˆtûˋ sur le fait qu'il ûˋtait possible de faire de la recherche de donnûˋes basûˋe sur des connaissances.
Admettons que nous ayons les assertions suivantesô :
- A1ô : un homme fait un match de tennis contre son frû´reô ;
- A2ô : une femme fait un match de tennis contre la fille de son frû´re.
Avec ces deux assertions, nous allons essayer de rûˋpondre û quelques requûˆtesô :
- requûˆte 1ô : ô¨ô un homme et un hommeô ô£ô ;
- requûˆte 2ô : ô¨ô un homme en relation avec une femmeô ô£ô ;
- requûˆte 3ô : ô¨ô une fille en relation avec un adulteô ô£ô ;
- requûˆte 4ô : ô¨ô une personne fait un match de tennis avec une autreô ô£ô ;
- la requûˆte 1 renvoieô : A1ô ;
- la requûˆte 2 renvoieô : rienô ;
- la requûˆte 3 renvoieô : peut-ûˆtre A2, mais pour afficher cela nous aurions besoin de plus de connaissances du domaine que l'on a introduitô ;
- la requûˆte 4 renvoieô : A1 et A2.
Vous avez pu voir que nous avons la possibilitûˋ de raisonner en fonction des rûˋponses.
Aprû´s ce petit exemple de rappel, nous pouvons revenir dans le vif du sujet. Sachant que ce tutoriel est orientûˋ Web sûˋmantique il faut savoir que sur le Web sûˋmantique, toutes les donnûˋes ne sont pas contenues dans une base de donnûˋes relationnelle, mais dans une base de connaissances, mais voyons ce qui compose ces bases de connaissancesô :
- un ensemble de classesô ;
- un ensemble de propriûˋtûˋsô ;
- ces ensembles sont en gûˋnûˋral ordonnûˋs (ou prûˋordonnûˋs) par ô¨ô spûˋcialisationô ô£. C'est-û -dire du terme le plus gûˋnûˋral au plus spûˋcifique.
Tout ceci forme une ontologie. Par exemple, les classes et propriûˋtûˋs que j'ai pu donner dans mon article prûˋcûˋdent pour la famille Simpson.
Dans le Web sûˋmantique, on peut dire que l'ontologie reprûˋsente toute la base de connaissances, car une ontologie = un domaine. Mais qu'est-ce que ûÏa veut direô ?
III. Systû´me et programmation û base de connaissances▲
En rû´gle gûˋnûˋrale comment fonctionne un systû´me û base de connaissancesô ?
Et bien c'est simple, nous avons d'un cûÇtûˋ une base de connaissances, qui ûˋchange des informations avec un moteur d'infûˋrences (une infûˋrence est un mode de raisonnement consistant û aller d'une connaissance û une autre qui lui est liûˋe) et qui lui-mûˆme ûˋchange des donnûˋes avec une base de faits, pour le Web sûˋmantique, le moteur d'infûˋrence classique est SPARQL. Par exemple, toujours pour le Web sûˋmantique, dans la recherche de donnûˋes, pour rûˋaliser un systû´me û base de connaissances il nous fautô :
- une ontologie correspondant au domaine des donnûˋesô ;
- des rû´gles complûˋtant l'ontologieô ;
- des faits qui sont des annotations (ou des donnûˋes sur des donnûˋes ou plus couramment appelûˋes mûˋtadonnûˋes).
Voyons maintenant un autre exemple, un programme qui, ûˋtant donnûˋ un arbre hiûˋrarchique, sait retrouver les chefs/subalternes d'une hiûˋrarchie. En rû´gle gûˋnûˋrale, on aurait dûˋveloppûˋ ce programme en reprûˋsentant l'arbre hiûˋrarchique par un graphe et l'on aurait ûˋcrit des algorithmes de manipulation de ce graphe correspondant û chaque type de l'arbre hiûˋrarchique (chefs, subalternes, etc.) Afin de les dûˋtecter.
Mais si l'on procû´de de cette maniû´re, cela peut poser plusieurs problû´mes, car il faudrait comprendre le fonctionnement de ces algorithmes et il aurait aussi fallu crûˋer un algorithme pour chaque autre type dans l'arbre hiûˋrarchique comme collû´gue ou bien associûˋ ou mûˆme DRH. C'est pour cette raison qu'il est prûˋfûˋrable de faire un programme qui prenne en compte les bases de connaissances. C'est-û -dire qu'û la place d'ûˋcrire des algorithmes pour trouver les diffûˋrents types de l'arbre hiûˋrarchique, on ûˋcrit des prûˋdicats qui reprûˋsentent le sens de ces types. Par exempleô :
- si chef(x,y) alors subalterne(y,x)ô ;
- si PDG(x,y) alors chef(x,y)ô ;
- si PDG(x,y) ou patron(x,y) alors chef(x,y)
- si chef(x,y) et chef(y,z) alors chef(x,z).
De cette maniû´re afin de comprendre ces rûˋsultats, il suffit d'assimiler la signification des prûˋdicats. On peut ainsi rajouter autant de rû´gles qu'on le souhaite û condition de garder la mûˆme base de connaissances.
Les moteurs d'infûˋrences contrûÇlent la cohûˋrence des donnûˋes contenues dans la base de connaissances et peuvent ainsi rûˋpondre û des requûˆtes.
IV. Diffûˋrents types de raisonnement▲
IV-A. Dûˋductif▲
Dans le raisonnement dûˋductif, on part d'une idûˋe gûˋnûˋrale, d'un principe, d'une loi pour en tirer une consûˋquence particuliû´re. Par exempleô : tout homme mange, or je suis un homme donc je mange.
IV-B. Inductif▲
Dans le raisonnement inductif, on part d'un ou de plusieurs faits particuliers pour en tirer un principe, une loi, une idûˋe gûˋnûˋrale. Ce raisonnement est l'inverse du raisonnement par dûˋduction. Par exempleô : tout homme, que je connais, mange, donc tout homme mange.
IV-C. Abductif▲
C'est un raisonnement dûˋductif qui tire une conclusion de deux propositions (ou prûˋmisses) prûˋsentûˋes comme vraies. On appelle ûÏa aussi un syllogisme. Par exempleô : tout homme mange, or je mange, donc je suis un homme.
Il existe aussi le raisonnement par analogie, oû¿ l'on compare la thû´se par une situation comparable et ceci pour dûˋfendre cette thû´se. Par exempleô : la raquette est au tennisman ce que le clavier est û l'informaticien.
V. Quel est le rûÇle de la logique en reprûˋsentation des connaissancesô ?▲
Prenons le rûˋseau sûˋmantique suivantô :
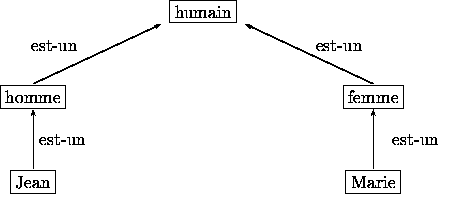
On peut voir que la vue de ce genre de schûˋma favorise beaucoup la comprûˋhension de ce que l'on veut reprûˋsenter, ici un rûˋseau sûˋmantique reprûˋsentant le genre masculin et fûˋminin d'un humain, mais malheureusement c'est insuffisant. La logique ici servira donc û dûˋcrire de maniû´re formelle et structurûˋe la connaissance d'un domaine. Nous aurons ainsi une ontologie bien plus prûˋcise avec cet outil de description et donc il n'y aura plus de confusion dans la comprûˋhension d'une ontologie.
VI. Monde ouvert et monde clos▲
Admettons un certain nombre de cours dans une universitûˋ quelconque. Chaque cours est identifiûˋ par un numûˋro.
- FMIN200ô ;
- FMIN201ô ;
- FMIN202ô ;
- FMIN209.
Nous voulons savoir combien de cours il existe dans cette universitûˋô :
- version base de donnûˋesô : 4 (count * from cours ---> 4)ô ;
- version logique de prûˋdicatô : c'est au moins 1, car rien ne dit que ces cours sont diffûˋrents ou qu'il n'y en a pas d'autresô ;
- version reprûˋsentation des connaissancesô : au moins 4, car on suppose que ces cours sont diffûˋrents, mais rien ne dit qu'il n'y en a pas d'autres.
Je pense que vous avez pu entrevoir ce que pouvait ûˆtre un peu le monde clos et ouvert, mais l'on va prûˋciser ces deux choses.
D'abord il faut savoir ce qu'est l'hypothû´se du nom unique, qui signifie que chaque constante reprûˋsentant une entitûˋ est diffûˋrente, on a donc par exempleô : FMIN200ô != FMIN201. Ceci est admis dans tous les domaines (base de donnûˋes et reprûˋsentation des connaissances) sauf en logique.
Ensuite, il y a l'hypothû´se du monde clos, c'est lorsqu'une chose est considûˋrûˋe comme fausse si pendant un certain temps il est impossible de montrer que cette chose est vraie. Mais il n'y a que pour les bases de donnûˋes que ûÏa marche, car dans une base de donnûˋes on sait oû¿ se situe chaque donnûˋe et donc il est possible de toujours la trouver dans un laps de temps dûˋfini.
Par opposition il y a donc ce que l'on appelle l'hypothû´se du monde ouvert, qui est tout l'inverse du monde clos. Mais plus prûˋcisûˋment dans ce monde ouvert, on ne peut pas dire qu'une chose n'existe pas tant qu'il n'a pas ûˋtûˋ explicitement statuûˋ qu'elle n'existait pas. Dit autrement, si une proposition n'a pas le statut ô¨ô Vraiô ô£, on ne peut pas en dûˋduire qu'elle est fausse. On dira que son cas n'a pas ûˋtûˋ statuûˋ, ou que l'on ne dispose pas des connaissances nûˋcessaires pour statuer. De fait, c'est bien utile lorsqu'on rûˋalise une ontologie, car cela permet de rendre compte du fait que certaines connaissances sont indisponibles sans pour autant rendre impossible la formalisation des connaissances d'un domaine. On sait que ô¨ô l'on ne sait pasô ô£, et le modû´le ne vous somme pas de prendre une dûˋcision. Le revers de la mûˋdaille, c'est que nous modûˋlisons souvent en ayant une pensûˋe binaire. Cela implique que nous raisonnons sur des choses en pensant qu'elles deviendront explicites ô¨ô par dûˋfautô ô£.
VII. Diffûˋrences entre base de donnûˋes et base de connaissances▲
Il faut savoir une chose û ce moment-lû , les bases de donnûˋes sont pour le Web classique (de documents) que l'on connaûÛt actuellement alors que les bases de connaissances sont pour le Web sûˋmantique.
Une base de donnûˋes est un lot de donnûˋes stockûˋes. Actuellement elles permettent d'organiser et de structurer ces donnûˋes de maniû´re û pouvoir plus facilement manipuler et stocker ces donnûˋes et surtout en trû´s grande quantitûˋ. On peut ainsi retrouver rapidement les donnûˋes que l'on cherche. Mais malgrûˋ les progrû´s de l'informatique, quelques problûˋmatiques sont toujours d'actualitûˋsô :
- les bases de donnûˋes contiennent des rû´gles en plus des tables, elles sont donc dûˋductivesô ;
- le Web sûˋmantique publie des bases de donnûˋes converties en base de connaissances, mais ces connaissances sont incomplû´tes, car les bases ne contiennent pas toutes les connaissances existantes sur un domaine. Mais heureusement ce problû´me peut ûˆtre trû´s facilement contournûˋ avec ce que l'on appelle l'interconnexion. Ce point sera vu dans un futur tutoriel.
VIII. Les ontologies dans le Web sûˋmantique▲
Les ontologies font partie intûˋgrante des normes du W3C pour le Web sûˋmantique, dans lequel elles sont utilisûˋes pour spûˋcifier la norme des vocabulaires conceptuels et dans lequel l'ûˋchange de donnûˋes entre diffûˋrents systû´mes a pour but de fournirô :
- des services pour rûˋpondre aux requûˆtesô ;
- de publier des bases de connaissances rûˋutilisablesô ;
- d'offrir des services pour faciliter l'interopûˋrabilitûˋ entre plusieurs systû´mes hûˋtûˋrogû´nes et bases de donnûˋes.
Le rûÇle clûˋ des ontologies par rapport aux systû´mes de base de donnûˋes est de spûˋcifier une reprûˋsentation de modûˋlisation des donnûˋes û un niveau d'abstraction au-dessus des schûˋmas d'une base de donnûˋes spûˋcifique (logique ou physique), afin que les donnûˋes puissent ûˆtre exportûˋes, traduites, interrogûˋes et unifiûˋes pour tous les systû´mes dûˋveloppûˋs de maniû´re indûˋpendante.
IX. Comment concevoir une ontologieô ?▲
Nous allons maintenant voir comment concevoir (et non dûˋvelopper, ce qui sera le thû´me d'un prochain article) une ontologie. L'ontologie que j'ai choisie est celle que l'on trouve sur le site du W3C sur la nourriture et le vin.
IX-A. ûtape 1ô : Dûˋterminer le domaine et la portûˋe de l'ontologie▲
Pour dûˋterminer le domaine et la portûˋe de l'ontologie, nous pouvons commencer par rûˋpondre û quelques questions et donc de schûˋmatiser une liste de questions auxquelles la base de connaissances fondûˋe sur cette ontologie devrait ûˆtre capable de rûˋpondre. Exemple de questions auxquelles notre base de connaissances doit pouvoir rûˋpondreô :
- quel est le domaine que l'ontologie couvriraô ? Reprûˋsentation des mets et des vinsô ;
- dans quel but allons-nous utiliser cette ontologieô ? Pour une application suggûˋrant par exemple quel vin va le mieux avec tel type de nourritureô ;
-
û quels types de questions l'information dans l'ontologie doit-elle rûˋpondreô ? Et qui va utiliser et maintenir l'ontologieô ?
- Si l'ontologie que nous concevons sera utilisûˋe pour aider dans le traitement du langage naturel d'un programme dans les vins, il peut ûˆtre important d'inclure des synonymes comme concepts dans l'ontologie.
- Si l'ontologie sera utilisûˋe pour aider les clients d'un restaurant û dûˋcider du vin qu'ils peuvent choisir, nous devons inclure le prix des vins.
- Si elle est utilisûˋe pour les acheteurs de vin pour leur cave û vin, le prix de gros et la disponibilitûˋ peuvent ûˆtre nûˋcessaires.
Et maintenant voici une liste de questions sur des compûˋtences auxquelles doit pouvoir rûˋpondre notre ontologieô :
- quelles caractûˋristiques je dois considûˋrer quand je choisis un vinô ?
- le Bordeaux est-il un vin blanc ou un vin rougeô ?
- le Cabernet Sauvignon est-il un vin qui va bien avec les fruits de merô ?
- quel est le meilleur choix de vin pour les viandes grillûˋesô ?
- quels ont ûˋtûˋ les bons millûˋsimes pour le Merlotô ?
û en juger par cette liste de questions, l'ontologie doit inclure les renseignements sur les caractûˋristiques du vin et divers types de vins, millûˋsimes, bonnes et mauvaises classifications des aliments qui comptent pour le choix d'un vin appropriûˋ puis recommander des combinaisons de vin et de nourriture. On peut bien entendu imaginer beaucoup plus de questions. Tout dûˋpend de tout ce que vous voulez reprûˋsenter avec votre ontologie.
IX-B. Rûˋutiliser des ontologies dûˋjû existantes▲
Rûˋutiliser des ontologies existantes peut ûˆtre une obligation si notre systû´me a besoin d'interagir avec d'autres applications qui utilisent dûˋjû des ontologies particuliû´res dans le domaine que nous voulons reprûˋsenter. Il est aussi inutile de refaire ce qui a dûˋjû ûˋtûˋ fait, assurez-vous aussi avant de commencer qu'il n'existe pas une ontologie qui ressemble û celle que vous voulez faire, quitte û la modifier en l'ûˋtendant avec d'autres classes et propriûˋtûˋs.
IX-C. ûnumûˋrer les termes importants de l'ontologie▲
Il faut aussi faire une liste de tous les termes existants, puisqu'il serait bien de pouvoir faire des dûˋclarations au sujet d'un vin afin d'expliquer toutes les facettes techniques d'un vin û une personne, sans se soucier du chevauchement entre les classes que les termes reprûˋsentent, les relations entre les termes, ou les propriûˋtûˋs que les classes peuvent avoir.
Par exempleô : raisin, cave, emplacement, couleur du vin, corps, saveur, teneur en sucre, diffûˋrents types d'aliments comme le poisson et la viande rouge, les sous-types de vin comme le vin blanc et le rosûˋ, etc.
IX-D. Dûˋfinir les classes et la hiûˋrarchie des classes▲
Dans cette ûˋtape, nous dûˋfinissons les classes. Pour dûˋfinir la hiûˋrarchie des classes, il y a trois approchesô :
- de haut en basô : dûˋfinir le concept gûˋnûˋral (super-classe) et ensuite dûˋfinir la sous-classeô ;
- de bas en hautô : dûˋfinir la sous-classe d'abord, puis la super-classeô ;
- combinaison de haut en bas et de bas en hautô : nous dûˋfinissons les classes les plus importantes d'abord, puis les gûˋnûˋraliser et les spûˋcialiser de faûÏon appropriûˋe au fur et û mesure de la conception. Cette approche est la plus facile û suivre.
Nous organisons les classes dans une taxonomie hiûˋrarchique pour se demander si en ûˋtant une instance d'une classe, l'objet sera nûˋcessairement (i.e. par dûˋfinition) une instance d'une autre classe.
Une classe A est une super-classe de la classe B si et seulement si chaque instance de B est ûˋgalement une instance de A. En d'autres termes, la classe B reprûˋsente une classe qui est une ô¨ô sorte deô ô£ A.
Par exemple, chaque vin Pinot noir est nûˋcessairement un vin rouge. Par consûˋquent, la classe Pinot noir est une sous-classe de la classe Vin rouge.
IX-E. Dûˋfinir les propriûˋtûˋs de l'ontologie▲
Chaque classe a des propriûˋtûˋs. Les propriûˋtûˋs d'une classe sont rattachûˋes û cette classe. En gûˋnûˋral, il existe plusieurs types de propriûˋtûˋs qui peuvent se trouver dans une base de connaissancesô :
- propriûˋtûˋs intrinsû´quesô : la propriûˋtûˋ intrinsû´que d'une chose est une propriûˋtûˋ qui est essentielle û la chose, qui perd son identitûˋ lorsque la propriûˋtûˋ change. Exemple: le goû£t du vinô ;
- propriûˋtûˋs extrinsû´ques. Exemple: le secteur de production du vin, etc.ô ;
- relationsô : quelles sont des relations entre les membres individuels de la classe. Par exempleô : le fabricant d'un vin, ce qui reprûˋsente une relation entre un vin et son producteur, le vin et le raisin qui le compose, le vin est fait û partir).
Voilû maintenant que vous savez comment concevoir une ontologie il ne vous reste plus qu'û reprûˋsenter cette ontologie avec des outils comme Protûˋgûˋ. L'utilisation de cet outil fera l'objet d'un prochain article.
X. Remerciements▲
Merci û dourouc05 pour son aide û la rûˋdaction de cet article. Ainsi qu'û ClaudeLELOUP pour la correction orthographique. Et û Marie Laure Mugnier pour son cours de reprûˋsentation des connaissances.