







I. Introduction▲
Le Web sûˋmantique (plus techniquement appelûˋ ô¨ô le Web de donnûˋesô ô£) permet aux machines de comprendre la sûˋmantique, la signification de l'information sur le Web. Il ûˋtend le rûˋseau des hyperliens entre des pages Web classiques par un rûˋseau de lien entre donnûˋes structurûˋes permettant ainsi aux agents automatisûˋs d'accûˋder plus intelligemment aux diffûˋrentes sources de donnûˋes contenues sur le Web et, de cette maniû´re, d'effectuer des tûÂches (recherche, apprentissage, etc.) plus prûˋcises pour les utilisateurs. Le terme a ûˋtûˋ inventûˋ par Tim Berners-Lee, co-inventeur du Web et directeur du W3C, qui supervise l'ûˋlaboration des propositions de standards du Web sûˋmantique.
La plupart du temps, lorsque l'on prononce le terme de Web sûˋmantique, on parle des diffûˋrentes technologies qui se cachent derriû´re. Parmi les plus connues, on peut citer RDF (Ressource Description Framework) qui correspond û un modû´le d'information, et les formats d'ûˋchanges de donnûˋes en RDF pour communiquer entre diffûˋrentes applications (RDF/XML, RDF/JSON, N3, Turtle, N-Triples et d'autres). Dans le domaine du Web sûˋmantique, la sûˋmantique des donnûˋes est dûˋcrite par des ontologies ãô ce terme sera dûˋfini plus loin dans l'articleô ã avec des langages prûˋvus pour fournir une description formelle de concepts, termes ou relations d'un domaine quelconque. Ces langages sont RDFS (Ressource Description Framework Schema) et OWL (Web Ontology Language). Il existe aussi des langages de description des donnûˋes structurûˋes dans du XHTML afin que des outils effectuent un traitement automatique de ces diffûˋrentes donnûˋes. Ces langages sont RDFa et Microformat et, nouvellement arrivûˋ avec HTMLô 5, Microdata. Voici d'ailleurs un article qui vous introduit le langage RDFa et un autre sur les Microdata. Ensuite, pour finir avec la liste des technologies, il existe un langage de requûˆte, au mûˆme titre que SQL pour les bases de donnûˋes relationnelles, SPARQL, qui effectue des requûˆtes, mais sur des triplets RDF. Il en existe d'autres (RQL et RDQL), mais ils sont bien moins utilisûˋs.
II. Histoire du Web sûˋmantique▲
En 1994, lors de la premiû´re confûˋrence WWW û Genû´ve, plus prûˋcisûˋment au CERN, a lieu l'annonce de la crûˋation du W3C. C'est d'ailleurs û cette pûˋriode que Tim Berners-Lee dresse les objectifs du W3C et montre les besoins d'ajouter de la sûˋmantique au Web futur. Il montre alors en quoi les liens hypertextes ou, plus prûˋcisûˋment, la faûÏon dont on met en relation les documents sur le Web est trop limitûˋe pour permettre aux machines de relier automatiquement les donnûˋes contenues sur le Web û la rûˋalitûˋ. Compte tenu de l'ambition d'un tel projet, cette idûˋe suscite quelques rûˋsistances et controverses qui sont classiquement rencontrûˋes dû´s qu'on aborde des problûˋmatiques liûˋes au domaine de l'intelligence artificielle.
Aprû´s cette confûˋrence, mise û part la mise en place des recommandations nûˋcessaires û la construction des documents, le W3C nouvellement crûˋûˋ entame les premiû´res rûˋflexions sur la mise en place du Web sûˋmantique. Ces rûˋflexions aboutissent û la publication d'un premier draft de recommandations sur le Web sûˋmantique en octobre 1997 et d'une seconde en avril 1998. Cette mûˆme annûˋe, Tim Berners-Lee publie un document sur les toutes premiû´res moutures de ce qui sera plus tard appelûˋ le Web sûˋmantique. Ces moutures consistent û mettre en place les diffûˋrentes technologies du Web sûˋmantique. Dans ce document, il prûˋsente le Web sûˋmantique comme une sorte d'extension du Web des documents, qui constitue une base de donnûˋes û l'ûˋchelle mondiale, afin que toutes les machines puissent mieux lier les donnûˋes du Web. Cette feuille de route se matûˋrialise par une reprûˋsentation graphique, le ô¨ô layer cakeô ô£, qui montre l'agencement des diffûˋrentes briques technologiques du Web sûˋmantique.

Par ailleurs, en 1999, Tim Berners-Lee publie le livre Weaving the Web dans lequel il dresse un portrait du Web et les pistes pour son avenir. Les idûˋes du Web sûˋmantique n'en sont ûˋvidemment pas absentes. C'est d'ailleurs cette mûˆme annûˋe qu'il ûˋnonûÏa sa cûˋlû´bre citationô :
I have a dream for the Web [in which computers] become capable of analyzing all the data on the Web ô the content, links, and transactions between people and computers. A ô¨ô Semantic Webô ô£, which should make this possible, has yet to emerge, but when it does, the day-to-day mechanisms of trade, bureaucracy and our daily lives will be handled by machines talking to machines. The ô¨ô intelligent agentsô ô£ people have touted for ages will finally materialize.
J'ai fait un rûˆve pour le Web [dans lequel les ordinateurs] deviennent capables d'analyser toutes les donnûˋes sur le Web ãô le contenu, les liens et les transactions entre les personnes et les ordinateurs. Un ô¨ô Web sûˋmantiqueô ô£, qui devrait rendre cela possible, n'est pas encore sorti, mais, quand ce sera le cas, les mûˋcanismes d'ûˋchange au jour le jour, la bureaucratie et notre vie quotidienne seront traitûˋes par des machines qui parlent û d'autres machines. Certains nous ont vantûˋ depuis des lustres les ô¨ô agents intelligentsô ô£ et cela va enfin se concrûˋtiser.
Citation provenant deô : https://en.wikipedia.org/wiki/Semantic_Web
III. Objectifs du Web sûˋmantique▲
Un des principaux objectifs du Web sûˋmantique est de permettre aux utilisateurs d'utiliser la totalitûˋ du potentiel du Webô : ainsi, ils pourront trouver, partager et combiner des informations plus facilement. Aujourd'hui tout le monde est capable d'utiliser des forums, d'utiliser des rûˋseaux sociaux, de chatter, de faire des recherches ou mûˆme d'acheter diffûˋrents produits. Nûˋanmoins, il serait mieux que la machine fasse tout ceci û la place de l'homme, car actuellement, les machines ont besoin de l'homme pour effectuer ces tûÂches. La raison principale est que les pages Web actuelles sont conûÏues pour ûˆtre lisibles par des ûˆtres humains et non par des machines. Le Web sûˋmantique a donc comme principal objectif que ces mûˆmes machines puissent rûˋaliser seules toutes les tûÂches fastidieuses comme la recherche ou l'association d'informations et d'agir sur le Web lui-mûˆme.
IV. Le Web sûˋmantique et le Web 3.0▲
La communautûˋ du Web dans son ensemble û tendance û dire que les deux termes ô¨ô Web sûˋmantiqueô ô£ et ô¨ô Webô 3.0ô ô£ reprûˋsentent û peu prû´s le mûˆme concept, si ce n'est pas totalement interchangeable. La dûˋfinition continue de varier en fonction des gens avec qui vous parlez. L'avis gûˋnûˋral est que le Webô 3.0 est trû´s certainement la prochaine grande rûˋvolution, mais il se trouve que, pour le moment, ce ne sont que des spûˋculations quant û ce qu'il pourrait ûˆtre. Il y aura encore de grosses amûˋliorations, mais en gardant la plupart des propriûˋtûˋs du Webô 2.0. Il y en a certains qui prûˋtendent que le Webô 3.0 sera plus applicatif et centrera ses efforts vers des environnements plus graphiques, d'autres qui prûˋtendent qu'il sera plus axûˋ sur la recherche d'informations gûˋographiques basûˋes sur la gûˋolocalisation ou encore mûˆme utiliser les nombreux progrû´s en intelligence artificielle.
V. Le Web sûˋmantique souvent critiquûˋ▲
Comme vous avez pu le deviner, le Web sûˋmantique permet û tous d'en savoir plus sur les sujets qui les intûˋressent. Cela signifie a contrario que diverses institutions peuvent rûˋcolter des informations sur vous librement et donc constituer des dossiers. Ces institutions peuvent ûˆtre des agences de publicitûˋ, de sûˋcuritûˋ ou mûˆme des services de renseignements. Et ceci tout en restant dans la lûˋgalitûˋ, car dans 90ô % des cas, ces informations sont mises en ligne volontairement ou non par les utilisateurs, sans qu'ils se doutent du ô¨ô dangerô ô£ que peut reprûˋsenter cette action.
Le Web sûˋmantique est aussi critiquûˋ û cause de sa lourdeurô : les langages utilisûˋs pour le Web sûˋmantique sont trû´s verbeux, car dûˋrivûˋs du XML et donc souvent pûˋnibles û utiliser. De ce fait, l'ûˋcriture d'ontologies est souvent trû´s problûˋmatique, car elle exige une spûˋcialisation dans un domaine particulier et, lorsque l'on ne maûÛtrise pas ce domaine, elle devient trû´s difficile û crûˋer. Ainsi, certaines personnes disent qu'il est prûˋfûˋrable d'utiliser des ô¨ô words tagsô ô£ (ce sont une sûˋrie de mots clûˋs qui permettent de qualifier une ressource) û la place des ontologies.
VI. L'ontologie, outil principal du Web sûˋmantique▲
Nous allons dans cette partie expliquer de maniû´re non technique ce qu'est une ontologie. Gardez aussi û l'esprit que c'est une introduction et que la faûÏon dont je dûˋfinis cet outil n'est pas û 100ô % exacte si l'on rentre dans les dûˋtails, mais vous permettra de comprendre facilement le principe.
VI-A. Dûˋfinition▲
L'ontologie est la base de ce que l'on appelle la reprûˋsentation des connaissances. Ce domaine est nûˋ de la volontûˋ des chercheurs de reprûˋsenter diverses connaissances du monde actuel, de faûÏon û ce qu'elles soient utilisables par des ordinateurs, pour qu'ils puissent effectuer des raisonnements sur ces connaissances. Ces connaissances sont exprimûˋes sous forme de symboles auxquels on donne une ô¨ô sûˋmantiqueô ô£ (un sens).
Imaginons la problûˋmatique suivanteô : vous voulez interroger une base de donnûˋes contenant diverses ressources (textes, images, vidûˋosãÎ) et une requûˆte (question ou mot(s) clûˋ(s)), comment trouver les donnûˋes se trouvant dans cette base qui correspondent û cette requûˆteô ?
Par exemple, tapez dans votre moteur de recherche prûˋfûˋrûˋ les mots suivantsô : ô¨ô ordinateur portableô ô£ puis ô¨ô laptopô ô£. Vous pouvez vous apercevoir que les rûˋsultats ne sont pas du tout les mûˆmes, alors que, vu que les deux mots reprûˋsentent la mûˆme chose, on pourrait s'attendre û trouver les mûˆmes rûˋponses.
Que se passe-t-ilô ? En fait, le moteur de recherche compare des mots sans prendre en compte leur sûˋmantique (sens). Il exûˋcute uniquement une recherche strictement syntaxique et donc sans rûˋflexion, car ô¨ô ordinateur portableô ô£ et ô¨ô laptopô ô£ reprûˋsentent le mûˆme concept (la mûˆme chose), que nous appellerons maintenant des classes pour respecter la terminologie du Web sûˋmantique. Plus prûˋcisûˋment, on peut dire que la relation de spûˋcialisation sur les classes n'est pas gûˋrûˋe. Par exemple, ô¨ô notebookô ô£ est une spûˋcialisation de la classe gûˋnûˋrale ô¨ô laptopô ô£. Ainsi, pour raisonner, il ne faut plus se baser sur les mots, mais sur les classes. Mais que signifie raisonnerô ? Raisonner c'est utiliser sa raison pour dûˋmontrer quelque chose. C'est un terme trû´s souvent employûˋ en intelligence artificielle.
Illustration en comparant deux moteurs de rechercheô :
Avec Orangeô : 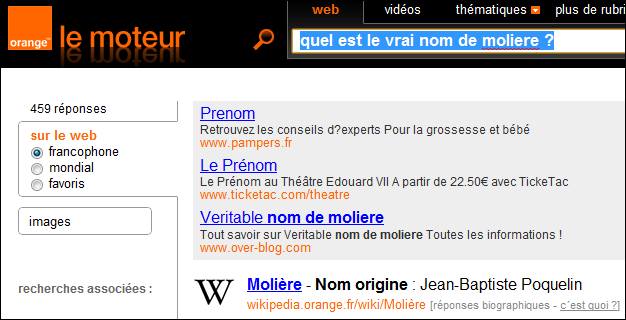
Avec Googleô : 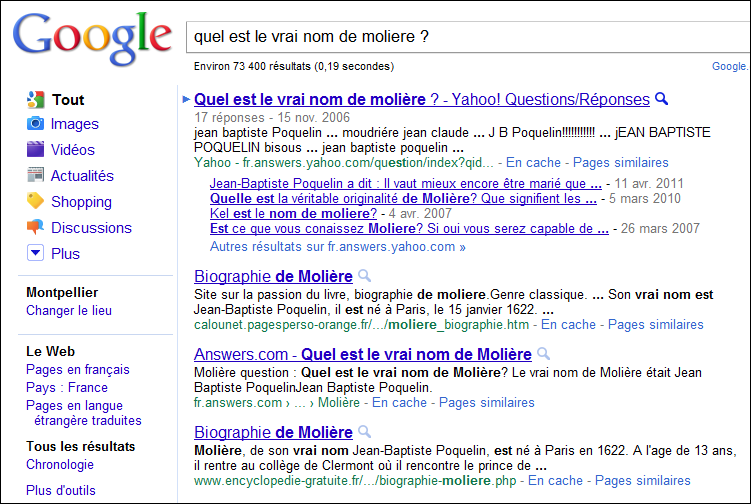
Vous pouvez donc voir que sur le moteur d'Orange, la premiû´re occurrence est la rûˋponse û notre question et qu'ensuite il y a les rûˋponses rûˋsultant de la recherche syntaxique. Alors que sur Google il n'y a que la recherche syntaxique. Cette diffûˋrence et tout simplement due û l'utilisation d'ontologies de la part du moteur d'Orange.
Ainsi pour rûˋsoudre ce problû´me, on construit ce que l'on appelle des bases de connaissances qui sont constituûˋesô :
- d'une ontologieô : une collection de classes et de relations (que nous appellerons propriûˋtûˋ pour les mûˆmes raisons que concept) entre ces classesô ;
- de rû´glesô : une expression de contraintes sur les propriûˋtûˋs et les classes de l'ontologieô ;
- de faitsô : des instances de l'ontologie.
VI-B. Exemple de construction d'une ontologie▲
Faisons maintenant un petit exemple d'ontologie sur la famille Simpson pour illustrer tout ceci. Tout d'abord les conceptsô : {Human, Child, Boy, Girl, Male, Man, Female, Woman, Adult} qui nous donne la reprûˋsentation suivante entre ces classesô :
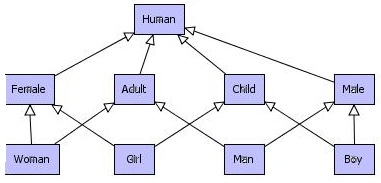
Ensuite, occupons-nous des propriûˋtûˋsô : {relatedWith(Human, Human), siblingOf(Human, Human), sisterOf(Female,Human), brotherOf(Male,Human), ancestorOf(Adult, Human), parentOf(Adult, Human), fatherOf(Man, Human), motherOf(Woman, Human), marriedTo(Adult, Adult), childOf(Human, Adult)}. Ce qui nous donne la reprûˋsentation suivante entre ces propriûˋtûˋsô :
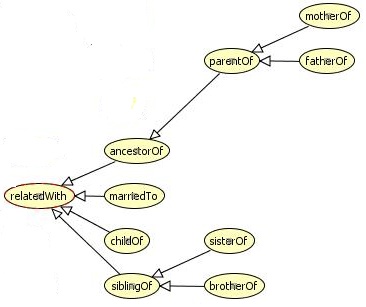
Maintenant, admettons quelques rû´gles, logiques pour un humain sur ces classes et propriûˋtûˋsô :
- rû´gle 1ô : si une classe ô¨ô Maleô ô£ appartient û une propriûˋtûˋ ô¨ô brotherOfô ô£ avec une classe ô¨ô Femaleô ô£ alors la classe ô¨ô Femaleô ô£ appartient û la propriûˋtûˋ ô¨ô sisterOfô ô£ avec la classe ô¨ô Maleô ô£ô ;
- rû´gle 2ô : rûˋciproque de la rû´gle 1ô ;
- rû´gle 3ô : si une classe ô¨ô Adultô ô£ appartient û une propriûˋtûˋ ô¨ô parentOfô ô£ avec une classe ô¨ô Humanô ô£ alors la classe ô¨ô Humanô ô£ appartient û la propriûˋtûˋ ô¨ô childOfô ô£ avec la classe ô¨ô Adultô ô£ô ;
- rû´gle 4ô : rûˋciproque de la rû´gle 3.
De cette maniû´re, on peut facilement imaginer toutes les rû´gles possibles entre ces propriûˋtûˋs et classes. Pour finir, prenons quelques instancesô : {Bart, Lisa, Homer}. On dit ensuite que l'instance ô¨ô Bartô ô£ appartient û la classe ô¨ô Boyô ô£, ô¨ô Lisaô ô£ appartient û la classe ô¨ô Girlô ô£ et ô¨ô Homerô ô£ appartient û la classe ô¨ô Manô ô£. On dit ensuite que ô¨ô Bartô ô£ est le frû´re de ô¨ô Lisaô ô£ et que ô¨ô Bartô ô£ et ô¨ô Lisaô ô£ sont les enfants de ô¨ô Homerô ô£ avec nos propriûˋtûˋs.
Notre ontologie ainsi construite, il nous est maintenant facile d'effectuer les requûˆtes suivantes dessusô :
- est-ce que Lisa est la séur de Bartô ?
- est-ce que Homer est un parent de Lisa et Bartô ?
Bien entendu cette ontologie est ridiculement petite et facile comparûˋe aux ontologies de domaines plus complexes. Mais, maintenant que vous savez ce qu'est une ontologie, vous pouvez vous amuser û continuer l'ontologie de la famille Simpson en ajoutant des propriûˋtûˋs, des classes, des rû´gles et des instances.
VI-C. Quelques ontologies dûˋjû existantes▲
VII. Conclusion▲
Vous en savez maintenant beaucoup plus sur le Web sûˋmantique et j'espû´re que je vous ai donnûˋ envie d'en apprendre plus sur ce domaine encore trop mûˋconnu.
VIII. Remerciements▲
Merci û dourouc05 pour son aide û la rûˋdaction de cet article. Ainsi qu'û ClaudeLELOUP et jacques_jean pour leur correction orthographique.